70-761 Study Guide
I have been examining Microsoft’s array of exams lately with the goal of gaining a few certifications. I’ve been building personal summary study guides to compare each of these certifications and then tackle the exams by easiest first.
This is the first of those study guides.
This is a study guide not in that it contains all info, but it’s an aggregate of all the places I need to go read the info. As well as some short text or code snippets to jumpstart my memory on the topic.
Microsoft Exam 70-761: Querying Data with Transact-SQL
Docker Run SQL Server 2017 (for local developer testing):
docker run --rm --name sql -e ACCEPT_EULA=Y -e MSSQL_SA_PASSWORD=P@ssw0rd -p 1433:1433 -d microsoft/mssql-server-linux:2017-latest
docker exec -it sql /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P P@ssw0rdContents
Manage data with Transact-SQL (40%-45%)
- Create Transact-SQL SELECT queries
- Identify proper SELECT query structure, write specific queries to satisfy business requirements, construct results from multiple queries using set operators, distinguish between UNION and UNION ALL behaviour, identify the query that would return expected results based on provided table structure and/or data
- Query multiple tables by using joins
- Write queries with join statements based on provided tables, data, and requirements; determine proper usage of INNER JOIN, LEFT/RIGHT/FULL OUTER JOIN, and CROSS JOIN; construct multiple JOIN operators using AND and OR; determine the correct results when presented with multi-table SELECT statements and source data; write queries with NULLs on joins
- Implement functions and aggregate data
- Construct queries using scalar-valued and table-valued functions; identify the impact of function usage to query performance and WHERE clause sargability; identify the differences between deterministic and non-deterministic functions; use built-in aggregate functions; use arithmetic functions, date-related functions, and system functions
- Modify data
- Write INSERT, UPDATE, and DELETE statements; determine which statements can be used to load data to a table based on its structure and constraints; construct Data Manipulation Language (DML) statements using the OUTPUT statement; determine the results of Data Definition Language (DDL) statements on supplied tables and data
Query data with advanced Transact-SQL components (30%-35%)
- Query data by using subqueries and APPLY
- Determine the results of queries using subqueries and table joins, evaluate performance differences between table joins and correlated subqueries based on provided data and query plans, distinguish between the use of CROSS APPLY and OUTER APPLY, write APPLY statements that return a given data set based on supplied data
- Query data by using table expressions
- Identify basic components of table expressions, define usage differences between table expressions and temporary tables, construct recursive table expressions to meet business requirements
- Group and pivot data by using queries
- Use windowing functions to group and rank the results of a query; distinguish between using windowing functions and GROUP BY; construct complex GROUP BY clauses using GROUPING SETS, and CUBE; construct PIVOT and UNPIVOT statements to return desired results based on supplied data; determine the impact of NULL values in PIVOT and UNPIVOT queries
- Query temporal data and non-relational data
- Query historic data by using temporal tables, query and output JSON data, query and output XML data
Program databases by using Transact-SQL (25%-30%)
- Create database programmability objects by using Transact-SQL
- Create stored procedures, table-valued and scalar-valued user-defined functions, and views; implement input and output parameters in stored procedures; identify whether to use scalar-valued or table-valued functions; distinguish between deterministic and non-deterministic functions; create indexed views
- Implement error handling and transactions
- Determine results of Data Definition Language (DDL) statements based on transaction control statements, implement TRY…CATCH error handling with Transact-SQL, generate error messages with THROW and RAISERROR, implement transaction control in conjunction with error handling in stored procedures
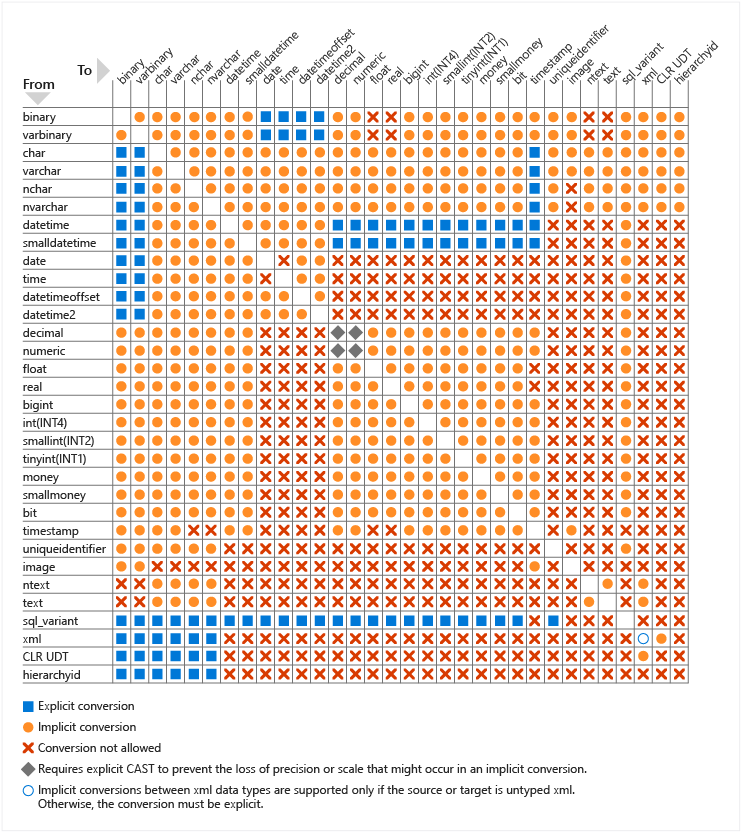
- Implement data types and NULLs
- Evaluate results of data type conversions, determine proper data types for given data elements or table columns, identify locations of implicit data type conversions in queries, determine the correct results of joins and functions in the presence of NULL values, identify proper usage of ISNULL and COALESCE functions
Study
1.) Create Transact-SQL SELECT queries
Identify proper SELECT query structure, write specific queries to satisfy business requirements, construct results from multiple queries using set operators, distinguish between UNION and UNION ALL behaviour, identify the query that would return expected results based on provided table structure and/or data
Examples
SELECT OrderDateKey, SUM(SalesAmount) AS TotalSales
FROM FactInternetSales
GROUP BY OrderDateKey
HAVING OrderDateKey > 20010000
ORDER BY OrderDateKey;2.) Query multiple tables by using joins
Write queries with join statements based on provided tables, data, and requirements; determine proper usage of INNER JOIN, LEFT/RIGHT/FULL OUTER JOIN, and CROSS JOIN; construct multiple JOIN operators using AND and OR; determine the correct results when presented with multi-table SELECT statements and source data; write queries with NULLs on joins
Examples
SELECT p.Name, sod.SalesOrderID
FROM Production.Product AS p
FULL OUTER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY p.Name ;3.) Implement functions and aggregate data
Construct queries using scalar-valued and table-valued functions; identify the impact of function usage to query performance and WHERE clause sargability; identify the differences between deterministic and non-deterministic functions; use built-in aggregate functions; use arithmetic functions, date-related functions, and system functions
Deterministic and Nondeterministic Functions
Deterministic functions always return the same result any time they are called with a specific set of input values and given the same state of the database. Nondeterministic functions may return different results each time they are called with a specific set of input values even if the database state that they access remains the same. For example, the function AVG always returns the same result given the qualifications stated above, but the GETDATE function, which returns the current datetime value, always returns a different result.
4.) Modify data
Write INSERT, UPDATE, and DELETE statements; determine which statements can be used to load data to a table based on its structure and constraints; construct Data Manipulation Language (DML) statements using the OUTPUT statement; determine the results of Data Definition Language (DDL) statements on supplied tables and data
5.) Query data by using subqueries and APPLY
Determine the results of queries using subqueries and table joins, evaluate performance differences between table joins and correlated subqueries based on provided data and query plans, distinguish between the use of CROSS APPLY and OUTER APPLY, write APPLY statements that return a given data set based on supplied data
A subquery is a query that is nested inside a SELECT, INSERT, UPDATE, or DELETE statement, or inside another subquery. A subquery can be used anywhere an expression is allowed.
Many queries can be evaluated by executing the subquery once and substituting the resulting value or values into the WHERE clause of the outer query. In queries that include a correlated subquery (also known as a repeating subquery), the subquery depends on the outer query for its values. This means that the subquery is executed repeatedly, once for each row that might be selected by the outer query.
SELECT
p.ProductID,
p.Name,
fn.Quantity
FROM
Production.Product AS p
OUTER APPLY
fn_inventory(p.ProductID) AS fn
ORDER BY p.ProductID6.) Query data by using table expressions
Identify basic components of table expressions, define usage differences between table expressions and temporary tables, construct recursive table expressions to meet business requirements
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
GO7.) Group and pivot data by using queries
Use windowing functions to group and rank the results of a query; distinguish between using windowing functions and GROUP BY; construct complex GROUP BY clauses using GROUPING SETS, and CUBE; construct PIVOT and UNPIVOT statements to return desired results based on supplied data; determine the impact of NULL values in PIVOT and UNPIVOT queries
- Window functions all use the OVER() clause, which is used to define how the function is evaluated. The OVER() clause accepts three different arguments:
- PARTITION BY: Resets its counter every time the stated column(s) changes values.
- ORDER BY: Orders the rows the function will evaluate. This does not order the entire result set, only the way the function proceeds through the rows.
- ROWS BETWEEN: Specifies how to further limit the rows evaluated by the function.
A GROUP BY clause that uses GROUPING SETS can generate a result set equvalent to that generated by a UNION ALL of multiple simple GROUP BY clauses. GROUPING SETS can generate a result equivalent to that generated by a simple GROUP BY, ROLLUP or CUBE operation. Different combinations of GROUPING SETS, ROLLUP, or CUBE can generate equivalent result sets.
--Equivalents
SELECT Country, Region, SUM(Sales) AS TotalSales
FROM Sales
GROUP BY GROUPING SETS ( ROLLUP (Country, Region), CUBE (Country, Region) );
SELECT Country, Region, SUM(Sales) AS TotalSales
FROM Sales
GROUP BY ROLLUP (Country, Region)
UNION ALL
SELECT Country, Region, SUM(Sales) AS TotalSales
FROM Sales
GROUP BY CUBE (Country, Region);GROUP BY CUBE creates groups for all possible combinations of columns. For GROUP BY CUBE (a, b) the results has groups for unique values of (a, b), (NULL, b), (a, NULL), and (NULL, NULL).
SELECT Country, Region, SUM(Sales) AS TotalSales
FROM Sales
GROUP BY CUBE (Country, Region);
--The query result has groups for unique values of (Country, Region), (NULL, Region), (Country, NULL), and (NULL, NULL). The results look like this:Creates a group for each combination of column expressions. In addition, it “rolls up” the results into subtotals and grand totals. To do this, it moves from right to left decreasing the number of column expressions over which it creates groups and the aggregation(s).
For example, GROUP BY ROLLUP (col1, col2, col3, col4) creates groups for each combination of column expressions in the following lists.
col1, col2, col3, col4
col1, col2, col3, NULL
col1, col2, NULL, NULL
col1, NULL, NULL, NULL
NULL, NULL, NULL, NULL --This is the grand total
Using the table from the previous example, this code runs a GROUP BY ROLLUP operation instead of a simple GROUP BY.
SELECT Country, Region, SUM(Sales) AS TotalSales
FROM Sales
GROUP BY ROLLUP (Country, Region);null values in the input of UNPIVOT disappear in the output, whereas there may have been original null values in the input before the PIVOT operation.
When aggregate functions are used with PIVOT, the presence of any null values in the value column are not considered when computing an aggregation.
--PIVOT
SELECT <non-pivoted column>,
[first pivoted column] AS <column name>,
[second pivoted column] AS <column name>,
...
[last pivoted column] AS <column name>
FROM
(<SELECT query that produces the data>)
AS <alias for the source query>
PIVOT
(
<aggregation function>(<column being aggregated>)
FOR
[<column that contains the values that will become column headers>]
IN ( [first pivoted column], [second pivoted column],
... [last pivoted column])
) AS <alias for the pivot table>
<optional ORDER BY clause>;--UNPIVOT
-- Create the table and insert values as portrayed in the previous example.
CREATE TABLE pvt (VendorID int, Emp1 int, Emp2 int,
Emp3 int, Emp4 int, Emp5 int);
GO
INSERT INTO pvt VALUES (1,4,3,5,4,4);
INSERT INTO pvt VALUES (2,4,1,5,5,5);
INSERT INTO pvt VALUES (3,4,3,5,4,4);
INSERT INTO pvt VALUES (4,4,2,5,5,4);
INSERT INTO pvt VALUES (5,5,1,5,5,5);
GO
-- Unpivot the table.
SELECT VendorID, Employee, Orders
FROM
(SELECT VendorID, Emp1, Emp2, Emp3, Emp4, Emp5
FROM pvt) p
UNPIVOT
(Orders FOR Employee IN
(Emp1, Emp2, Emp3, Emp4, Emp5)
)AS unpvt;
GO8.) Query temporal data and non-relational data
Query historic data by using temporal tables, query and output JSON data, query and output XML data
SELECT C.query('.') as result
FROM Production.ProductModel
CROSS APPLY Instructions.nodes('
declare namespace MI="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelManuInstructions";
/MI:root/MI:Location') as T(C)
WHERE ProductModelID=7USE AdventureWorks2012
GO
SELECT Cust.CustomerID,
OrderHeader.CustomerID,
OrderHeader.SalesOrderID,
OrderHeader.Status
FROM Sales.Customer Cust
INNER JOIN Sales.SalesOrderHeader OrderHeader
ON Cust.CustomerID = OrderHeader.CustomerID
FOR XML AUTOSELECT PersonID,FullName,
JSON_QUERY(CustomFields,'$.OtherLanguages') AS Languages
FROM Application.People
SELECT FirstName, LastName,
JSON_VALUE(jsonInfo,'$.info.address[0].town') AS Town
FROM Person.Person
WHERE JSON_VALUE(jsonInfo,'$.info.address[0].state') LIKE 'US%'
ORDER BY JSON_VALUE(jsonInfo,'$.info.address[0].town')-- Nested JSON Output FOR JSON PATH
SELECT TOP 5
BusinessEntityID As Id,
FirstName, LastName,
Title As 'Info.Title',
MiddleName As 'Info.MiddleName'
FROM Person.Person
FOR JSON PATHUse the AS OF sub-clause when you need to reconstruct state of data as it was at any specific time in the past. You can reconstruct the data with the precision of datetime2 type that was specified in PERIOD column definitions. The AS OF sub-clause clause can be used with constant literals or with variables, which allows you to dynamically specify time condition. The values provided values are interpreted as UTC time.
DECLARE @ADayAgo datetime2
SET @ADayAgo = DATEADD (day, -1, sysutcdatetime())
/*Comparison between two points in time for subset of rows*/
SELECT D_1_Ago.[DeptID], D.[DeptID],
D_1_Ago.[DeptName], D.[DeptName],
D_1_Ago.[SysStartTime], D.[SysStartTime],
D_1_Ago.[SysEndTime], D.[SysEndTime]
FROM [dbo].[Department] FOR SYSTEM_TIME AS OF @ADayAgo AS D_1_Ago
JOIN [Department] AS D ON D_1_Ago.[DeptID] = [D].[DeptID]
AND D_1_Ago.[DeptID] BETWEEN 1 and 5 ;9.) Create database programmability objects by using Transact-SQL
Create stored procedures, table-valued and scalar-valued user-defined functions, and views; implement input and output parameters in stored procedures; identify whether to use scalar-valued or table-valued functions; distinguish between deterministic and non-deterministic functions; create indexed views
CREATE [ OR ALTER ] { PROC | PROCEDURE }
[schema_name.] procedure_name [ ; number ]
[ { @parameter [ type_schema_name. ] data_type }
[ VARYING ] [ = default ] [ OUT | OUTPUT | [READONLY]
] [ ,...n ]
[ WITH <procedure_option> [ ,...n ] ]
[ FOR REPLICATION ]
AS { [ BEGIN ] sql_statement [;] [ ...n ] [ END ] }
[;]
<procedure_option> ::=
[ ENCRYPTION ]
[ RECOMPILE ]
[ EXECUTE AS Clause ]-- Transact-SQL Scalar Function Syntax
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type
[ = default ] [ READONLY ] }
[ ,...n ]
]
)
RETURNS return_data_type
[ WITH <function_option> [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN scalar_expression
END
[ ; ]
-- Transact-SQL Inline Table-Valued Function Syntax
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ = default ] [ READONLY ] }
[ ,...n ]
]
)
RETURNS TABLE
[ WITH <function_option> [ ,...n ] ]
[ AS ]
RETURN [ ( ] select_stmt [ ) ]
[ ; ]
-- Transact-SQL Multi-Statement Table-Valued Function Syntax
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ = default ] [READONLY] }
[ ,...n ]
]
)
RETURNS @return_variable TABLE <table_type_definition>
[ WITH <function_option> [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN
END
[ ; ]CREATE [ OR ALTER ] VIEW [ schema_name . ] view_name [ (column [ ,...n ] ) ]
[ WITH <view_attribute> [ ,...n ] ]
AS select_statement
[ WITH CHECK OPTION ]
[ ; ]
<view_attribute> ::=
{
[ ENCRYPTION ]
[ SCHEMABINDING ]
[ VIEW_METADATA ]
}CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
GO
--Create an index on the view.
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
GO10.) Implement error handling and transactions
Determine results of Data Definition Language (DDL) statements based on transaction control statements, implement TRY…CATCH error handling with Transact-SQL, generate error messages with THROW and RAISERROR, implement transaction control in conjunction with error handling in stored procedures
BEGIN TRY
{ sql_statement | statement_block }
END TRY
BEGIN CATCH
[ { sql_statement | statement_block } ]
END CATCH
[ ; ]| RAISERROR | THROW |
|---|---|
| If a msg_id is passed to RAISERROR, the ID must be defined in sys.messages. | The error_number parameter does not have to be defined in sys.messages. |
| The msg_str parameter can contain printf formatting styles. | The message parameter does not accept printf style formatting. |
| The severity parameter specifies the severity of the exception. | There is no severity parameter. The exception severity is always set to 16. |
THROW [ { error_number | @local_variable },
{ message | @local_variable },
{ state | @local_variable } ]
[ ; ]11.) Implement data types and NULLs
Evaluate results of data type conversions, determine proper data types for given data elements or table columns, identify locations of implicit data type conversions in queries, determine the correct results of joins and functions in the presence of NULL values, identify proper usage of ISNULL and COALESCE functions